The post Touch Base Meeting: A Comprehensive Guide appeared first on Krisp.
]]>A touch base meeting is a regular, often informal meeting where team members check in with each other to discuss ongoing projects, address any issues, and align on goals. Unlike formal meetings that may have a strict agenda and structure, touch base meetings are typically more flexible and conversational, focusing on maintaining open lines of communication within the team.
Definition and Purpose
The primary purpose of a touch base meeting is to ensure that all team members are on the same page regarding project status, upcoming tasks, and any potential issues. These meetings can be scheduled regularly, such as weekly, or on an ad-hoc basis as needed.
Historical Context
The concept of touch base meetings has evolved over the years as businesses recognized the need for more frequent and less formal check-ins. Originally used as a way to maintain regular contact in large, dispersed organizations, they have become a staple in modern team management.
How Touch Base Meetings Work
Touch-based meetings are more like catch-up meetings. Contrary to some beliefs, they are informal in nature and are only organized to get reports on the progress rather than calling out or reprimanding anyone — meaning you should not fret whenever your supervisor asks for a touch base meeting.
Unlike lengthy and comprehensive meetings, touch base meetings are designed to be concise and frequent, promoting regular updates without consuming excessive time. They often occur on a daily or weekly basis, depending on the nature of the project and the team’s needs.
Moreover, the effectiveness of touch base meetings lies in their simplicity and focus on key objectives. Here’s how they work:
Frequency and duration
Touch-based meetings are typically short, lasting around 10 to 15 minutes. Their brevity ensures that participants remain engaged and that the meeting doesn’t disrupt the workflow.
Daily or weekly touch-base meetings allow teams to stay updated without overwhelming their schedules.
Agenda
While touch-base meetings are brief, they are not haphazard. Having an effective meeting agenda is still essential to maintain focus.
The agenda usually includes updates on tasks accomplished since the last meeting, ongoing tasks, potential challenges, and any immediate assistance required.
This structure keeps discussions organized and prevents the meeting from deviating into unrelated topics.
Attendance
Touch-base meetings involve only the relevant stakeholders. Attendees may include team members, project managers, supervisors, and other individuals directly associated with the project.
This selective approach prevents unnecessary overcrowding and ensures that the meeting remains concise.
Open communication
Participants openly share updates and challenges they are facing. Honest communication is crucial during these meetings to identify potential bottlenecks early on and find swift solutions. This fosters a culture of transparency and accountability within the team.
Decision-making
While touch-base meetings are not intended for in-depth discussions, they can still lead to important decisions.
If a challenge or roadblock is discussed, the team can decide whether further action or a dedicated meeting is necessary to resolve the issue.
Action Items
At the end of the meeting, action items are defined. These are specific tasks or objectives that need to be addressed before the next touch base meeting. Assigning action items helps in maintaining a sense of progress and accountability.
Why Touch Base Meetings are Important
Touch base meetings play a crucial role in maintaining effective communication and ensuring that everyone on the team is aligned with the project’s goals and objectives. Here are some key benefits:
- Improved Communication: Regular check-ins ensure that everyone is on the same page, reducing misunderstandings and miscommunication. When team members frequently touch base, they have more opportunities to clarify uncertainties, share updates, and synchronize their efforts, fostering a more cohesive working environment.
- Alignment on Goals: These meetings help keep everyone focused on the same objectives, ensuring that all team members are working towards the same end goal. This alignment is particularly important in dynamic environments where priorities can shift rapidly. Regular touch points ensure that everyone is aware of any changes in direction or focus.
- Increased Productivity: By addressing issues promptly and keeping the team informed, touch base meetings can boost overall productivity. When team members know they will have regular opportunities to discuss their progress and challenges, they are more likely to stay on track and proactive in their work.
- Enhanced Team Morale: Regular interaction helps build stronger relationships within the team, fostering a collaborative and supportive environment. Team members who feel heard and supported are generally more engaged and motivated.
Types of Touch Base Meetings
There are several types of touch base meetings, each serving different purposes and needs:
Weekly Touch Base Meetings
Weekly touch base meetings are scheduled at the same time each week. They provide a consistent platform for discussing progress, addressing any roadblocks, and planning for the upcoming week. A typical agenda might include updates from each team member, a review of key metrics, and a discussion of upcoming priorities. Weekly meetings are beneficial because they establish a routine, making it easier to maintain momentum and ensure continuous progress.
Ad-hoc Touch Base Meetings
These meetings are scheduled as needed, rather than on a regular basis. They are useful for addressing urgent issues or discussing new developments that arise between regular meetings. Ad-hoc meetings can be particularly effective for quick decision-making and immediate problem-solving. For example, if a critical issue arises that needs immediate attention, an ad-hoc touch base can help resolve it promptly without waiting for the next scheduled meeting.
One-on-One Touch Base Meetings
One-on-one meetings between managers and team members provide an opportunity for personalized feedback and support. These meetings can help managers address individual concerns, offer guidance, and build stronger relationships with team members. One-on-one meetings are also an excellent opportunity for employees to discuss their career development, seek mentorship, and receive constructive feedback in a private setting.
Best Practices for Effective Touch Base Meetings
To make the most out of your touch base meetings, follow these best practices:
Preparation
- Importance of an Agenda: Even though touch base meetings are often informal, having a loose agenda can help keep the meeting focused and productive. Outline key topics to discuss and set clear objectives. An agenda ensures that all necessary topics are covered and helps prevent the meeting from veering off track.
- Scheduling and Consistency: Schedule meetings at regular intervals and stick to the schedule to maintain consistency and reliability. Consistent scheduling helps team members prepare in advance and ensures that the meetings become a regular part of their routine.
During the Meeting
- Tips on Maintaining Focus: Keep the meeting focused on the key topics and avoid going off on tangents. Use a timer if necessary to ensure the meeting stays on track. Staying focused helps make the meeting more efficient and ensures that all important topics are addressed.
- Encouraging Participation: Foster an environment where everyone feels comfortable sharing their thoughts and ideas. Encourage participation by asking open-ended questions and actively listening to each team member. When team members feel that their input is valued, they are more likely to contribute actively.
- Effective Time Management: Respect everyone’s time by starting and ending the meeting on time. If necessary, assign a timekeeper to help manage the meeting duration. Effective time management ensures that meetings are productive and do not overrun, which can lead to frustration and decreased productivity.
Post-Meeting Follow-up
- Importance of Action Items: Clearly define action items and assign responsibilities during the meeting. Ensure that everyone knows what they need to do next. Action items help translate discussion into tangible tasks that drive progress.
- Methods for Tracking Progress: Use tools like project management software to track progress on action items and follow up regularly to ensure tasks are being completed. Regular follow-up ensures accountability and helps keep projects on track.
Common Challenges and How to Overcome Them
Touch base meetings can face several challenges, but with the right strategies, these can be effectively managed:
Challenges
- Time Management: Meetings can sometimes run over time, leading to wasted productivity. Overlong meetings can also lead to participant fatigue and disengagement.
- Participation: Some team members may be hesitant to speak up or participate actively. This can result in an unbalanced discussion where only a few voices are heard.
- Relevance: Without proper focus, meetings can become irrelevant or off-topic. This can lead to frustration among team members who feel that their time is being wasted.
Solutions
- Actionable Tips for Time Management: Set strict time limits for each agenda item and use tools like timers to stay on track. Keep the meeting concise and focused. Clearly communicate the meeting’s time constraints to all participants and ensure that discussions remain goal-oriented.
- Encouraging Participation: Create an inclusive environment by rotating the role of meeting facilitator and encouraging quieter team members to share their thoughts. Use techniques like round-robin discussions or directed questions to ensure that everyone has an opportunity to speak.
- Maintaining Relevance: Keep meetings goal-oriented by sticking to the agenda and steering conversations back to the main topics when necessary. Remind participants of the meeting’s objectives and gently redirect off-topic discussions.
Touch Base Meeting Templates
Using templates can help structure your touch base meetings efficiently. Here are a few examples:
Weekly Touch Base Meeting Template
- Introduction: Briefly go over the meeting objectives.
- Updates: Each team member provides a quick update on their progress.
- Challenges: Discuss any roadblocks or issues.
- Next Steps: Outline action items and assign responsibilities.
- Closing: Summarize key points and confirm the next meeting time.
Ad-hoc Touch Base Meeting Template
- Introduction: Explain the purpose of the meeting.
- Discussion: Focus on the urgent issue or new development.
- Decision-Making: Make any necessary decisions or plans.
- Next Steps: Assign action items and responsibilities.
- Closing: Recap and confirm follow-up actions.
One-on-One Touch Base Meeting Template
- Introduction: Greet and outline the meeting purpose.
- Feedback: Provide feedback and discuss individual performance.
- Goals: Review and set personal goals.
- Support: Identify any support or resources needed.
- Closing: Summarize and confirm follow-up.
Providing downloadable templates in your article can add significant value for readers, making it easier for them to implement the practices discussed.
Introducing Krisp AI Meeting Assistant
To enhance your touch base meetings, consider using Krisp AI Meeting Assistant. Krisp offers a range of features designed to improve virtual meetings, including:
- Noise Cancellation: Krisp effectively cancels out background noise, ensuring clear communication. This feature is particularly useful for remote teams where participants may be joining from various environments with potential background noise.
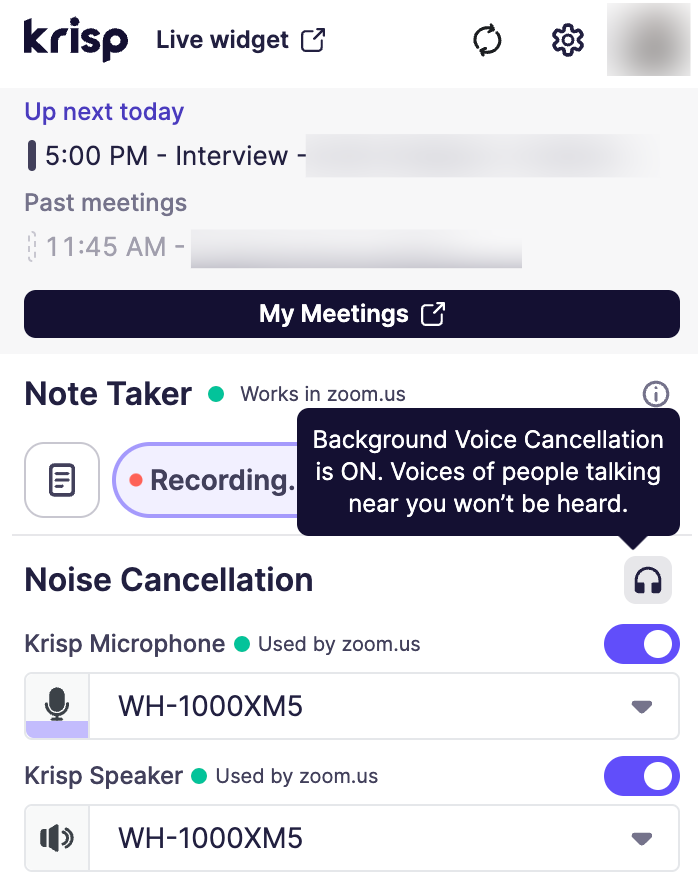
- Background Voice Cancellation: This feature removes unwanted background voices, allowing only the main speaker to be heard. It ensures that the meeting remains focused and free from distractions.
- Transcription: Krisp provides real-time transcription, making it easy to keep accurate meeting notes. Transcriptions can be reviewed later, ensuring that no important details are missed.
- Note Taking: The note-taking feature allows for easy capture and organization of key points during the meeting. Participants can quickly jot down important points, action items, and decisions.
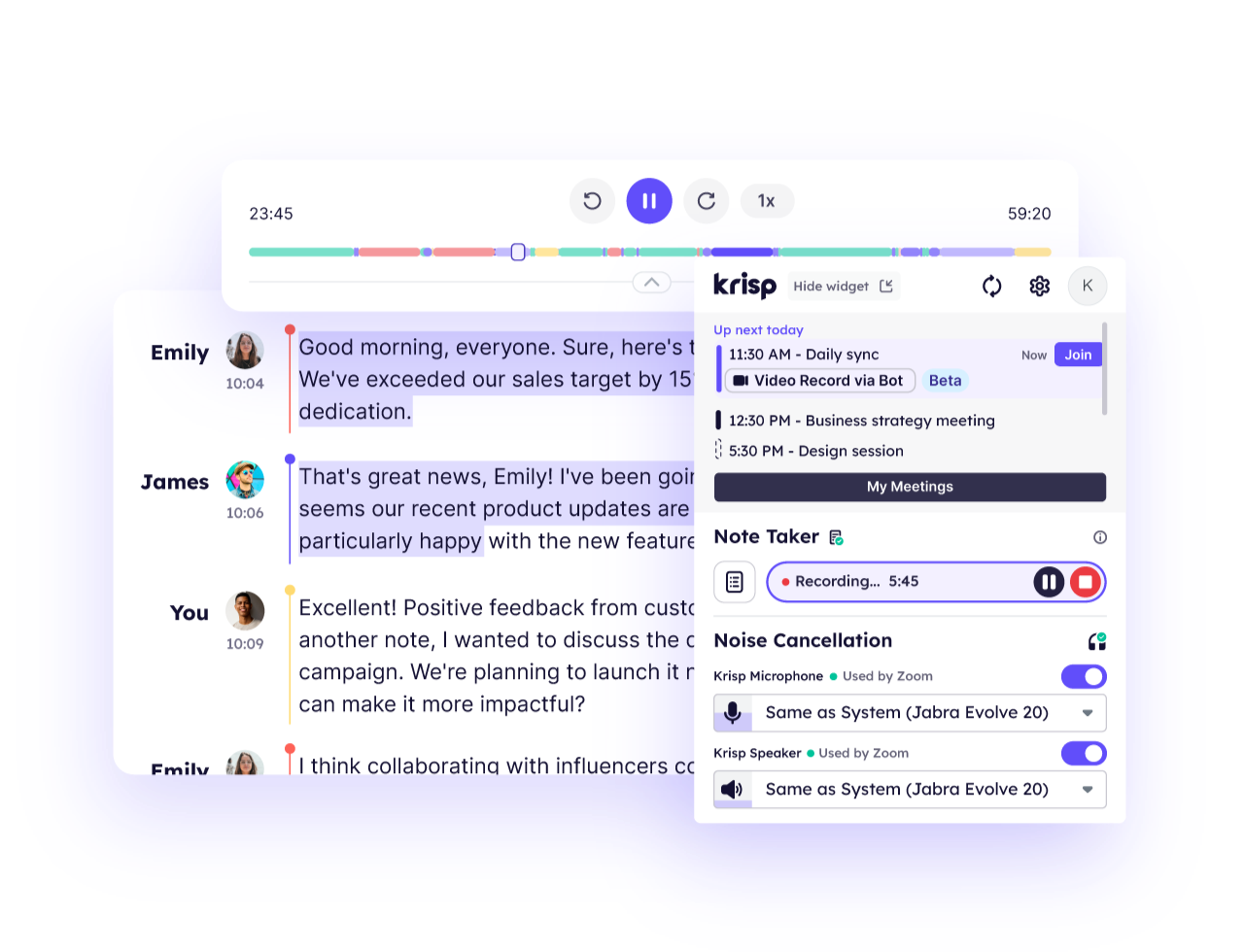
- Recording: Krisp allows you to record meetings, so you can review them later or share with team members who couldn’t attend. This feature is valuable for ensuring that everyone has access to the meeting’s content, even if they couldn’t join live.
By incorporating Krisp into your touch base meetings, you can avoid miscommunication, enhance audio quality, and ensure that every meeting is productive and efficient. Krisp’s features help create a seamless meeting experience, making it easier to focus on the content of the discussion rather than technical issues.
Conclusion
Touch base meetings are a vital tool for maintaining effective communication and alignment within teams. By understanding their importance, implementing best practices, and overcoming common challenges, you can ensure that your touch base meetings are successful and productive.
Additionally, using tools like Krisp can further enhance the quality of your virtual meetings, helping you achieve better results and fostering a more collaborative team environment. Try Krisp today and experience the difference it can make in your touch base meetings.
FAQs about Touch Base Meetings
The post Touch Base Meeting: A Comprehensive Guide appeared first on Krisp.
]]>The post Krisp launches Accent Localization SDK Early Access Program for Communications Providers appeared first on Krisp.
]]>
Krisp’s Accent Location SDKs are available initially for Windows OS and will become available for browser applications via WASM JS later this year. AI Accent Localization dynamically adjusts contact center agents’ accent to the natively understood accent of the customer calling them. Krisp’s AI Accent Localization supports India and the Philippines, due to their predominantly US-based customer market. Agents and administrators can select one of five output voices for both male and female agents. Like all other Krisp technologies, AI Accent Localization processes voice exclusively on-device, minimizing latency and maximizing quality, while preserving privacy and security.
“A number of our leading AI Noise Cancellation customers are already moving forward, integrating and testing Krisp’s AI Accent Localization SDKs,” said Robert Schoenfield, EVP of Licensing and Partnerships at Krisp. “We are thrilled to be diversifying our offerings and opening up our Early Access program to other CCaas providers as well.”
Krisp SDKs process more than 75 billion minutes of audio every month, supporting leading enterprise contact centers, BPOs and CCaaS platforms directly and through partnerships globally.
AI Accent Localization revolutionizes customer service for companies by eliminating the need for resource and cognitive-intensive accent neutralization training and puts all call center agents on an equal playing field. This allows contact centers to rapidly scale operations from any location in the world by increasing access to a larger employable talent pool, while delivering consistent, superior service without additional resources.
Krisp Accent Localization supports a wide range of Indian and Filipino accent dialects, making it an ideal solution for BPOs with India and Philippine-based contact center operations. Soon to follow are accent localization packs for English-speaking Latin American, South African and other contact center agents.
About Krisp
Founded in 2017, Krisp pioneered the world’s first AI-powered Voice Productivity software. Krisp’s Voice AI technology enhances digital voice communication through audio cleansing, noise cancelation, accent localization, and call transcription and summarization. Offering full privacy, Krisp works on-device, across all audio hardware configurations and applications that support digital voice communication. Today, Krisp processes over 75 billion minutes of voice conversations every month, eliminating background noise, echoes, and voices in real-time, helping businesses harness the power of voice to unlock higher productivity and deliver better business outcomes.
Learn more about Krisp’s SDK for developers.
The post Krisp launches Accent Localization SDK Early Access Program for Communications Providers appeared first on Krisp.
]]>The post Krisp launches On-Device Transcription SDKs for Integration appeared first on Krisp.
]]>
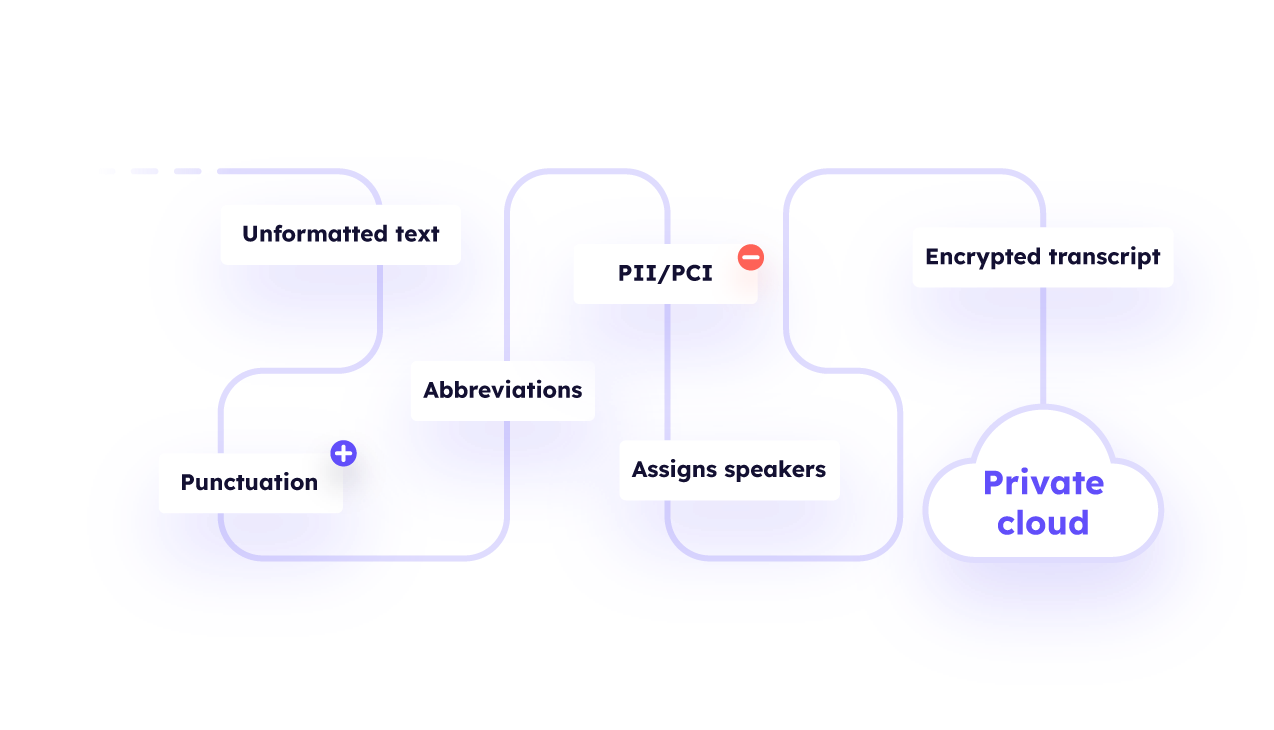
How it works: Krisp STT employs noise-robust deep learning algorithms for real-time on-device speech-to-text conversion. The process consists of several stages, including processing and turning speech into unformatted text, adding punctuation, capitalization and numerical values, redacting PII/PCI, and removing filler words on-device, in real-time. It then assigns text to speakers with timestamps before securely transmitting the encrypted transcript to a private cloud within each application.
“The success of our on-device transcriptions within the Krisp app has fueled demand for our STT SDKs,” said Robert Schoenfield, EVP of Licensing and Partnerships at Krisp. “Krisp STT SDKs are uniquely suited for applications and devices that require secure and accurate on-device transcriptions without the need of servers or an internet connection.”
Since introducing Transcriptions and Meeting Notes within the Krisp application, end users have generated more than 50 million hours of transcriptions. Today, Krisp STT SDKs are available for English and are speaker-accent robust, with plans to add other languages later this year including French, Spanish, and German. Krisp STT SDKs are also noise robust, as the underlying model is trained with noise represented in many use cases.
Krisp STT SDKs are available today for Windows, Mac and Linux, with support for browser-based applications via WASM JS becoming available in the second half of the year. Krisp SDKs deliver industry-leading performance on-device while consuming minimal CPU and memory resources.
About Krisp
Founded in 2017, Krisp pioneered the world’s first AI-powered Voice Productivity software. Krisp’s Voice AI technology enhances digital voice communication through audio cleansing, noise cancelation, accent localization, and call transcription and summarization. Offering full privacy, Krisp works on-device, across all audio hardware configurations and applications that support digital voice communication. Today, Krisp processes over 75 billion minutes of voice conversations every month, eliminating background noise, echoes, and voices in real-time, helping businesses harness the power of voice to unlock higher productivity and deliver better business outcomes.
Learn more about Krisp’s SDK for developers.
The post Krisp launches On-Device Transcription SDKs for Integration appeared first on Krisp.
]]>The post Krisp Delivers AI-Powered Voice Clarity to Symphony’s Trader Voice Products appeared first on Krisp.
]]>BERKELEY, Calif., April 17, 2024 – Krisp, the world’s leading AI-powered voice productivity software, announced today a new integration with Symphony’s trader voice platform, Cloud9, to enhance voice audio clarity. The partnership delivers Krisp’s advanced AI Noise Cancellation, enabling Cloud9 users to experience clear audio in challenging environments, such as trading floors and busy offices.
Through the integration, Symphony will also be able to enhance its built-for-purpose financial markets voice analytics in partnership with Google Cloud. By creating a space of uninterrupted audio between counterparties both on and off of Cloud9, more efficient communication is allowed with fewer disagreements. Accurate transcription of audio recordings is enhanced with compliance review in mind.
“We are thrilled to partner with Symphony and integrate our Voice AI technology into their products,” said Robert Schoenfield, EVP of Licensing and Partnerships at Krisp. “Symphony’s customers operate in difficult noisy environments, dealing with high value transactions. Improving their communication is of real value.”
Symphony’s chief product officer, Michael Lynch, said: “Cloud9 SaaS approach to trader voice gives our users the flexibility to work from anywhere, whether it’s a bustling trading desk or their living room, and KRISP improves our already best-in-class audio quality to help our users make the best possible real-time decisions while also improving post-trade analytics and compliance.”
This collaboration not only brings improved communication quality but also aligns with Krisp’s and Symphony’s commitment to bringing industry-leading solutions to their customers.
About Krisp
Founded in 2017, Krisp pioneered the world’s first AI-powered Voice Productivity software. Krisp’s Voice AI technology enhances digital voice communication through audio cleansing, noise cancelation, accent localization, and call transcription and summarization. Offering full privacy, Krisp works on-device, across all audio hardware configurations and applications that support digital voice communication. Today, Krisp processes over 75 billion minutes of voice conversations every month, eliminating background noise, echoes, and voices in real-time, helping businesses harness the power of voice to unlock higher productivity and deliver better business outcomes.
Learn more about Krisp’s SDK for developers.
Press contact:
Shara Maurer
Head of Corporate Marketing
[email protected]
About Symphony
Symphony is the most secure and compliant markets’ infrastructure and technology platform, where solutions are built or integrated to standardize, automate and innovate financial services workflows. It is a vibrant community of over half a million financial professionals with a trusted directory and serves over 1000 institutions. Symphony is powering over 2,000 community built applications and bots. For more information, visit www.symphony.com.
Press contact:
Odette Maher
Head of Communications and Corporate Affairs
+44 (0) 7747 420807 / [email protected]
The post Krisp Delivers AI-Powered Voice Clarity to Symphony’s Trader Voice Products appeared first on Krisp.
]]>The post Vonage to Launch Enhanced Noise Cancellation Powered by Krisp’s Voice AI appeared first on Krisp.
]]>
BERKELEY, CALIF., (March 26 2024) Vonage, a global leader in cloud communications helping businesses accelerate their digital transformation and a part of Ericsson, has announced the addition of Vonage Enhanced Noise Cancellation to Vonage Contact Center (VCC). This noise and echo cancellation feature uses Krisp’s machine learning technology to eliminate disruptive background noises and voices, boosting agent productivity, reducing average handle time, and improving the overall customer experience.
Through Krisp’s proprietary Voice AI technology, Vonage Enhanced Noise Cancellation is one of the only offerings on the market with noise cancellation fully embedded and available out of the box, eliminating the need for onsite developers or IT departments to manually integrate the technology. Users simply click to add the noise canceling feature in the VCC dashboard. Unique to this feature is its ability to cancel noise and voices around agents and any inbound noise behind the caller, providing an exceptionally clear connection, and a better experience for all.
In addition to eliminating local and remote audio quality issues – including removal of background voices, fan sounds, pet sounds, acoustic echo, and more – Vonage Enhanced Noise Cancellation enables better recordings, and more accurately captures call data to deliver superior analytics by extracting more meaningful insights, such as customer behavior and agent performance. This drives improved efficiency and customer support and overall better communication on the leading method of connecting agents and customers.
“The ongoing prevalence of voice in a world where consumers are connecting with businesses and their favorite brands from literally anywhere has driven a considerable demand for clear, concise and noise-free, two-way connections,” said Mary Wardley, VP, Customer Service and Contact Center for IDC. “Vonage’s introduction of Enhanced Noise Cancellation provides an immediate and effective way to improve customer experiences that drive engagement while also providing better recordings and analytics to help businesses resolve issues faster and gain better insights that drive data-driven decisions.”
“Audio quality is often a concern when it comes to a busy contact center environment, and the addition of inbound noise from a caller can make the experience a challenging one,” said Savinay Berry, EVP Product and Engineering for Vonage. “By embedding the technology to ensure optimal audio quality from within the Vonage Contact Center, agents are more productive and more efficient while providing a better experience for customers. This seamless experience helps drive the kind of personal and meaningful engagement that leads to long-lasting customer relationships.”
“Customer communications with contact centers should only be focused on solving issues and extending services, and agents should not have concern or angst about the noises and other voices around them,” said Robert Schoenfield, EVP of Licensing and Partnerships at Krisp. “Krisp’s Voice AI technology, integrated seamlessly within Vonage Contact Center, delivers on the promise of clear communications for agents and customers on every call, no matter the environment on either side of the call.”
Vonage customer Champion Power Equipment, a global market leader in power generation equipment, relies on Vonage Enhanced Noise Cancellation to help its agents diagnose and triage inbound callers seeking service on equipment.
“At Champion Power Equipment, the Vonage Contact Center has been a game-changer in our customer support journey. The Enhanced Noise Cancellation feature’s remarkable effectiveness in minimizing background noise has transformed the way our agents handle inbound calls, leading to quicker resolution and heightened customer satisfaction,” said Pedram Koukia, Customer Service Supervisor for Champion Power Equipment, Inc.
Koukia continued, “With a notable 20 percent decrease in call abandonment rates and a remarkable 25 percent increase in first-call issue resolution, Vonage has become an indispensable asset in our commitment to delivering seamless service and maintaining our reputation as a global leader in power generation equipment.”
Lowell Five Savings Bank, a Boston area savings and financial institution for more than 165 years, has employed Enhanced Noise Cancellation to its Vonage Contact Center solution, which serves its in-office agents: “Most of our agents are in-house and noise is a frequent challenge, not only for the productivity of our agents but in enabling them to deliver a personal and private experience for our clients. With Vonage Enhanced Noise Cancellation, that is no longer an issue,” said the Contact Center Manager for Lowell Five Savings Bank. “Our agents are empowered with the tools they need to provide every client with the kind of one-on-one engagement that makes them feel comfortable and heard and that ultimately drives loyalty and repeat business.”
Vonage Enhanced Noise Cancellation is currently in beta and will be Generally Available in April 2024. To date, more than 100,000 calls into VCC and a total of 350,000 minutes have been completed by Vonage customers using Vonage Enhanced Noise Cancellation. A demo of this new feature will be available in the Vonage Booth #818 at Enterprise Connect March 25 – 28, 2023, at the Gaylord Palms Convention Center in Orlando, Florida.
About Vonage
Vonage, a global cloud communications leader, helps businesses accelerate their digital transformation. Vonage’s Communications Platform is fully programmable and allows for the integration of Video, Voice, Chat, Messaging, AI and Verification into existing products, workflows and systems. The Vonage conversational commerce application enables businesses to create AI-powered omnichannel experiences that boost sales and increase customer satisfaction. Vonage’s fully programmable unified communications, contact center and conversational commerce applications are built from the Vonage platform and enable companies to transform how they communicate and operate from the office or remotely – providing the flexibility required to create meaningful engagements.
Vonage is headquartered in New Jersey, with offices throughout the United States, Europe, Israel and Asia and is a wholly-owned subsidiary of Ericsson (NASDAQ: ERIC), and a business area within the Ericsson Group called Business Area Global Communications Platform. To follow Vonage on X (formerly known as Twitter), please visit twitter.com/vonage. To follow on LinkedIn, visit linkedin.com/company/Vonage/. To become a fan on Facebook, go to facebook.com/vonage. To subscribe on YouTube, visit youtube.com/vonage.
About Krisp
Founded in 2017, Krisp pioneered the world’s first AI-powered Voice Productivity software. Krisp’s Voice AI technology enhances digital voice communication through audio cleansing, noise cancelation, accent localization, and call transcription and summarization. Offering full privacy, Krisp works on-device, across all audio hardware configurations and applications that support digital voice communication. Today, Krisp has transcribed over 20 million calls and processes over 75 billion minutes of voice conversations every month, helping businesses harness the power of voice to unlock higher productivity and deliver better business outcomes.
Learn more about Krisp SDKs here.
This announcement originally appeared on Vonage.com
The post Vonage to Launch Enhanced Noise Cancellation Powered by Krisp’s Voice AI appeared first on Krisp.
]]>The post Krisp and CarrierX’s FreeConferenceCall.com Integrate to Deliver AI-Powered Voice Clarity and Noise Cancellation appeared first on Krisp.
]]>
FreeConferenceCall.com offers a suite of advanced features, including secure conferences with access codes and user roles, the ability to control behavior through DTMF and API controls for participant muting and meeting recording, and the capability to accommodate up to 1,000 callers per meeting. This cost effective but powerful solution empowers businesses and individuals to conduct seamless and productive conferences while maintaining security and control over their communication sessions.
With Krisp’s advanced Voice AI software now integrated into CarrierX’s services solution, participants will experience unparalleled audio clarity during their conference calls. Krisp’s technology sets the standard in audio cleansing, noise cancellation, and overall voice quality across digital voice communications. By eliminating background noise, echoes, and other disturbances in real-time, Krisp ensures that every participant’s voice is clear and distinct, regardless of the call environment.
“We are excited to bring Krisp’s state-of-the-art Voice AI technology to CarrierX’s FreeConferenceCall.com,” said Robert Schoenfield, EVP of Licensing and Partnerships at Krisp. “By combining the capabilities of CarrierX’s conferencing features with Krisp’s AI-powered voice clarity, we are redefining the standard for high-quality conference calls and unlocking new possibilities for productivity and collaboration.”
“Since Day 1, CarrierX has been committed to providing best-in-class collaboration tools to customers, irrespective of geography or economics, ” said Andy Nickerson, CEO of CarrierX. “Integrating Krisp into FreeConferenceCall.com gives users more premium features to effectively and securely communicate without compromising quality for cost.”
The integration of Krisp and CarrierX’s Conference Endpoint solution underscores the commitment of both companies to deliver exceptional communication experiences and improve the quality of digital voice interactions everywhere.
With the integration of Krisp, CarrierX customers now experience conference calls that are secure, feature-rich, and deliver impeccable voice quality for all participants.
About Krisp:
Krisp pioneered the world’s first AI-powered Voice Productivity software. Krisp’s Voice AI technology enhances digital voice communication through audio cleansing, noise cancelation, accent localization, and call transcription and summarization for individuals, developers, and businesses worldwide. Offering full privacy, Krisp works on-device, across all audio hardware configurations and applications that support digital voice communication. Today, Krisp has transcribed over 20 million calls and processes over 75 billion minutes of voice conversations every month, helping individuals and businesses harness the power of voice to unlock higher productivity.
Learn more about Krisp’s SDKs and begin your evaluation today.
About CarrierX:
CarrierX is a leading provider of advanced communication solutions, offering a range of services for businesses and individuals. With a commitment to innovation and quality, CarrierX delivers reliable and cutting-edge communication tools to enhance connectivity and collaboration. The Conference Endpoint solution features secure conferences with access codes and user roles, DTMF and API controls, and support for up to 1,000 callers per meeting. For more information, visit www.carrierx.com/conference-endpoint.
The post Krisp and CarrierX’s FreeConferenceCall.com Integrate to Deliver AI-Powered Voice Clarity and Noise Cancellation appeared first on Krisp.
]]>The post Twilio Partners with Krisp to Provide AI Noise Cancellation to All Twilio Voice Customers appeared first on Krisp.
]]>How Krisp AI Noise Cancellation works
Trusted by more than 100 million users to process over 75 billion minutes of calls monthly, Krisp’s Voice AI SDKs are designed to identify human voice and cancel all background noise and voices to eliminate distractions on calls. Krisp SDKs are available for browsers (WASM JS), desktop apps (Win, Mac, Linux) and mobile apps (ioS, Android.) The Krisp Audio Plugin for Twilio Voice is a lightweight audio processor that can run inside your client application and create crystal clear audio.
The plugin needs to be loaded alongside the Twilio SDK and runs as part of the audio pipeline between the microphone and audio encoder in a preprocessing step. During this step, the AI-based noise cancellation algorithm removes unwanted sounds like barking dogs, construction noises, honking horns, coffee shop chatter and even other voices.
After the preprocessing step, the audio is encoded and delivered to the end user. Note that all of these steps happen on device, with near zero latency and without any media sent to a server.
Requirements and considerations
Krisp’s AI Noise Cancellation requires you to host and serve the Krisp audio plugin for Twilio Voice as part of your web application. It also requires browser support of the WebAudio API (specifically Worklet.addModule). Krisp has a team ready to support your integration and optimization for great voice quality.
Learn more about Krisp here and apply for access to the world’s best Voice AI SDKs.
Get started with AI Noise Cancellation
Visit the Krisp for Twilio Voice Developers page to request access to the Krisp SDK Portal. Once access is granted, download Krisp Audio JS SDK and place it in the assets of your project. Use the following code snippet to integrate the SDK with your project. Read the comments inside the code snippets for additional details.

Visit Krisp for Twilio Voice Developers and get started today.
The post Twilio Partners with Krisp to Provide AI Noise Cancellation to All Twilio Voice Customers appeared first on Krisp.
]]>The post On-Device STT Transcriptions: Accurate, Secure and Less Expensive appeared first on Krisp.
]]>
The on-device requirement has in many ways shaped the technical specifications of the technology and posed a series of challenges that the team has been able to tackle head-on, working through various iterations. The path to achieving high quality on-device STT continues, as the Krisp app has now transcribed over 15 million hours of calls and the company is now making this technology for its license partners via on-device SDKs. Let’s dive into the specific challenges Krisp worked through to bring this technology to market.
Challenges and solutions to on-device STT
Resource constraints
Without diving into the specifics of on-device STT technology and its architecture, one of the first and obvious constraints that the development had to be guided by was the computational resource. On-device STT systems operate within the confines of limited resources, including CPU, memory, and power. Unlike cloud-based solutions, which can leverage expansive server infrastructure, on-device systems must deliver comparable performance with significantly restricted resources. This constraint necessitates the optimization of algorithms, models, and processing pipelines to ensure efficient resource utilization without compromising accuracy and responsiveness. In many use cases, STT would need to run alongside the Noise Cancellation and other technologies, which further impacts the overall available bandwidth of resources.
Model complexity and size
The effectiveness of STT models hinges on their complexity and size, with larger models generally exhibiting superior accuracy and robustness. However, deploying large models on-device presents a formidable challenge, as it exacerbates memory and processing overheads. Balancing model complexity and size becomes paramount, requiring developers to employ techniques like model pruning, quantization, and compression to achieve optimal trade-offs between performance and resource utilization.
In order to achieve high quality transcripts and feature-rich speech-to-text systems, there is a need to build complex network architectures consisting of a number of AI models and algorithms. Such models include language models, punctuation and text normalization, speaker diarization and personalization (custom vocabulary) models, each presenting unique technical challenges and performance considerations.
The technology that Krisp employs both in its app and SDKs includes a combination of all of the above-mentioned technologies, as well as other adjacent algorithms to ensure readability and grammatical coherence of the final output.
The language model enhances transcription accuracy by predicting the likelihood of word sequences based on contextual and syntactic information. It helps in disambiguating words and improving the coherence of transcribed text. The Punctuation & Capitalization Model predicts the appropriate punctuation marks and capitalization based on speech patterns and semantic cues, enhancing the readability and comprehension of transcribed text. While the Inverse Text Normalization model standardizes and formats transcribed text to adhere to predefined conventions, such as converting numbers to textual representations or vice versa, expanding abbreviations, and correcting spelling errors. For cases where customers might have domain-specific terminology or proper names that are not widely recognized by the standard models, Krisp also provides Custom Vocabulary support.
Apart from the features ensuring text readability and accuracy, a major important technology included in Krisp’s on-device STT is Speaker Diarization. This model segments speech into distinct speaker segments, enabling the identification and differentiation of multiple speakers within a conversation or audio stream. It is crucial for speaker-dependent processing and improving transcription accuracy in multi-speaker scenarios.
Real or near real-time processing for on-device STT
Depending on a use case, on-device STT technology might have to deliver real or near real-time processing capabilities to enable seamless user interactions across diverse applications. Achieving low-latency speech recognition necessitates streamlining inference pipelines, minimizing computational overheads, and optimizing signal processing algorithms. Moreover, the heterogeneity of device architectures and hardware accelerators further complicates real-time performance optimization, requiring tailored solutions for different platforms and configurations. Krisp developers have achieved a delicate balance between latency, selecting optimal model combinations, ensuring processing synergy, and addressing the scalability and flexibility of the pipeline to accommodate various use-cases.
Robustness to variability
With a global and multi-domain user-base, there is an inherent variability of speech arising from diverse accents, vocabularies, environments, and speaking styles. Our on-device STT technology must exhibit robustness to such variability to ensure consistent performance across disparate contexts. This entails training models on diverse datasets, augmenting training data to encompass various scenarios, and implementing robust feature extraction techniques capable of capturing salient speech characteristics while mitigating noise and various device or network-dependent distortions.
In addition to addressing resource constraints and optimizing algorithms for on-device STT, Krisp prioritizes rigorous speech recognition testing to ensure its technology’s robustness across diverse accents, environments, and speaking styles.
Integration & embeddability of on-device STT
Along with being on-device, the technologies underlying the Krisp app AI Meeting Assistant are also designed with embeddability in mind. Integrating on-device STT technology into communication applications and devices presents a range of additional challenges, all of which Krisp has tackled. Resources must be carefully allocated to ensure optimal performance without compromising existing customer infrastructure. Customization and configuration options are essential to meet the diverse needs of end-users while maintaining scalability and performance across large-scale deployments. Security and compliance considerations demand robust encryption and privacy measures to protect sensitive data. Seamless integration with existing infrastructure, including telephony systems and collaboration tools, requires interoperability standards, codec support and integration frameworks.
One prevailing requirement for communication services is for on-device STT technology to be functional on the web. This presents a new set of challenges in terms of further resource optimization, as well as compatibility across diverse web platforms, browsers, frameworks and devices.
Bringing it all together
While the integration of on-device STT technology into communication applications and devices presents challenges and requires meticulous resource utilization, customization, and seamless interoperability, Krisp has addressed these challenges and today delivers embedded STT solutions that enhance the functionality and value proposition for applications and their end-users.
Try next-level on-device STT, audio and voice technologies
Krisp licenses its SDKs to embed directly into applications and devices. Learn more about Krisp’s SDKs and begin your evaluation today.

The post On-Device STT Transcriptions: Accurate, Secure and Less Expensive appeared first on Krisp.
]]>The post Deep Dive: AI’s Role in Accent Localization for Call Centers appeared first on Krisp.
]]>
Accent refers to the distinctive way in which a group of people pronounce words, influenced by their region, country, or social background. In broad terms, English accents can be categorized into major groups such as British, American, Australian, South African, and Indian among others.
Accents can often be a barrier to communication, affecting the clarity and comprehension of speech. Differences in pronunciation, intonation, and rhythm can lead to misunderstandings.
While the importance of this topic goes beyond call centers, our primary focus is this industry.
Offshore expansion and accented speech in call centers
The call center industry in the United States has experienced substantial growth, with a noticeable surge in the creation of new jobs from 2020-onward, both on-shore and globally.

In 2021, many US based call centers expanded their footprints thanks to the pandemic-fueled adoption of remote work, but growth slowed substantially in 2022. Inflated salaries and limited resources drove call centers to deepen their offshore operations, both in existing and new geographies.
There are several strong incentives for businesses to expand call centers operations to off-shore locations, including:
- Cost savings: Labor costs in offshore locations such as India, the Philippines, and Eastern Europe are up to 70% lower than in the United States.
- Access to diverse talent pools: Offshoring enables access to a diverse talent pool, often with multilingual capabilities, facilitating a more comprehensive customer support service.
- 24/7 coverage: Time zone differences allow for 24/7 coverage, enhancing operational continuity.
However, offshore operations come with a cost. One major challenge offshore call centers face is decreased language comprehension. Accents, varying fluency levels, cultural nuances and inherent biases lead to misunderstandings and frustration among customers.
According to Reuters, as many as 65% of customers have cited difficulties in understanding offshore agents due to language-related issues. Over a third of consumers say working with US-based agents is most important to them when contacting an organization.
Ways accents create challenges in call centers
While the world celebrates global and diverse workforces at large, research shows that misalignment of native language backgrounds between speakers leads to a lack of comprehension and inefficient communication.
- Longer calls: Thick accents contribute to comprehension difficulties, causing higher average handle time (AHT) and also lower first call resolutions (FCR).
According to ContactBabel’s “2024 US Contact Center Decision Maker’s Guide” the cost of mishearing and repetition per year for a 250-seat contact center exceeds $155,000 per year.
- Decreased customer satisfaction: Language barriers are among the primary contributors to lower customer satisfaction scores within off-shore call centers. According to ContactBabel, 35% of consumers say working with US-based call center agents is most important to them when contacting an organization.
- High agent attrition rates: Decreased customer satisfaction and increased escalations create high stress for agents, in turn decreasing agent morale. The result is higher employee turnover rates and short-term disability claims. In 2023, US contact centers saw an average annual agent attrition rate of 31%, according to The US Contact Center Decision Makers’ Guide to Agent Engagement and Empowerment.
- Increased onboarding costs: The need for specialized training programs to address language and cultural nuances further adds to onboarding costs.
- Limited talent pool: Finding individuals who meet the required linguistic criteria within the available talent pool is challenging. The competitive demand for specialized language skills leads to increased recruitment costs.
How do call centers mitigate accent challenges today?
Training
Accent neutralization training is used as a solution to improve communication clarity in these environments. Call Centers invest in weeks-long accent neutralization training as part of agent onboarding and ongoing improvement. Depending on geography, duration, and training method, training costs can run $500-$1500 per agent during onboarding. The effectiveness of these training programs can be limited due to the inherent challenges in altering long-established accent habits. So, call centers may find it necessary to temporarily remove agents from their operational roles for further retraining, incurring additional costs in the process.

Limited geography for expansion
Call centers limit their site selection to regions and countries where accents of the available talent pool is considered to be more neutral to the customer’s native language, sacrificing locations that would be more cost-effective.

Enter AI-Powered Accent Localization
Recent advancements in Artificial Intelligence have introduced new accent localization technology. This technology leverages AI to translate source accents to targets accent in real-time, with the click of a button. While the technologies in production don’t support multiple accents in parallel, over time this will be solved as well.
State of the Art AI Accent Localization Demo
Below is the evolution of Krisp’s AI Accent Localization technology over the past 2 years.
| Version | Demo |
|---|---|
| v0.1 First model | |
| v0.2 A bit more natural sound | |
| v0.3 A bit more natural sound | |
| v0.4 Improved voice | |
| v0.5 Improved intonation transfer |
This innovation is revolutionary for call centers as it eliminates the need for difficult and expensive training and increases the talent pool worldwide, providing immediate scalability for offshore operations.
It’s also highly convenient for agents and reduces the cognitive load and stress they have today. This translates to decreased short-term disability claims and attrition rates, and overall improved agent experience.
Deploying AI Accent Localization in the call center
There are various ways AI Accent Localization can be integrated into a call center’s tech stack.
It can be embedded into a call center’s existing CX software (e.g. CCaaS and UCaaS) or installed as a separate application on the agent’s machine (e.g. Krisp).
Currently, there are no CX solutions in market with accent localization capabilities, leaving the latter as the only possible path forward for call centers looking to leverage this technology today.
Applications like Krisp have accent localization built in their offerings.
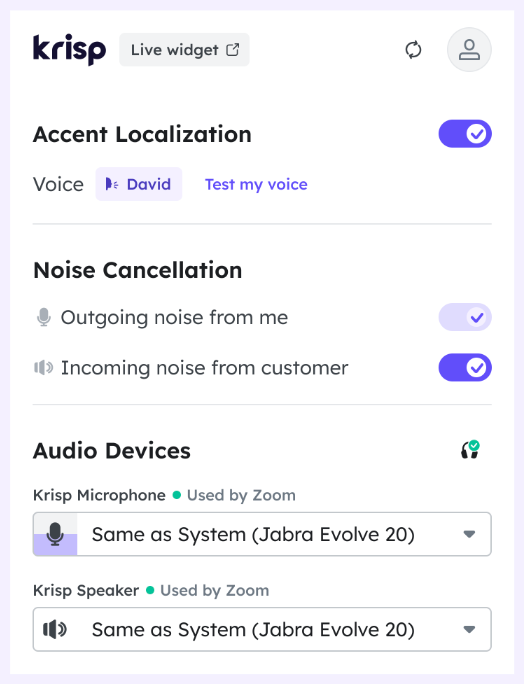
These applications are on-device, meaning they sit locally on the agent’s machine. They support all CX software platforms out of the box since they are installed as a virtual microphone and speaker.
AI runs on an agent’s device so there is no additional load on the network.
The deployment and management can be done remotely, and at scale, from the admin dashboard.
Challenges of building AI Accent Localization technology
At a fundamental level, speech can be divided into 4 parts: voice, text, prosody and accent.
Accents can be divided into 4 parts as well – phoneme, intonation, stress and rhythm.
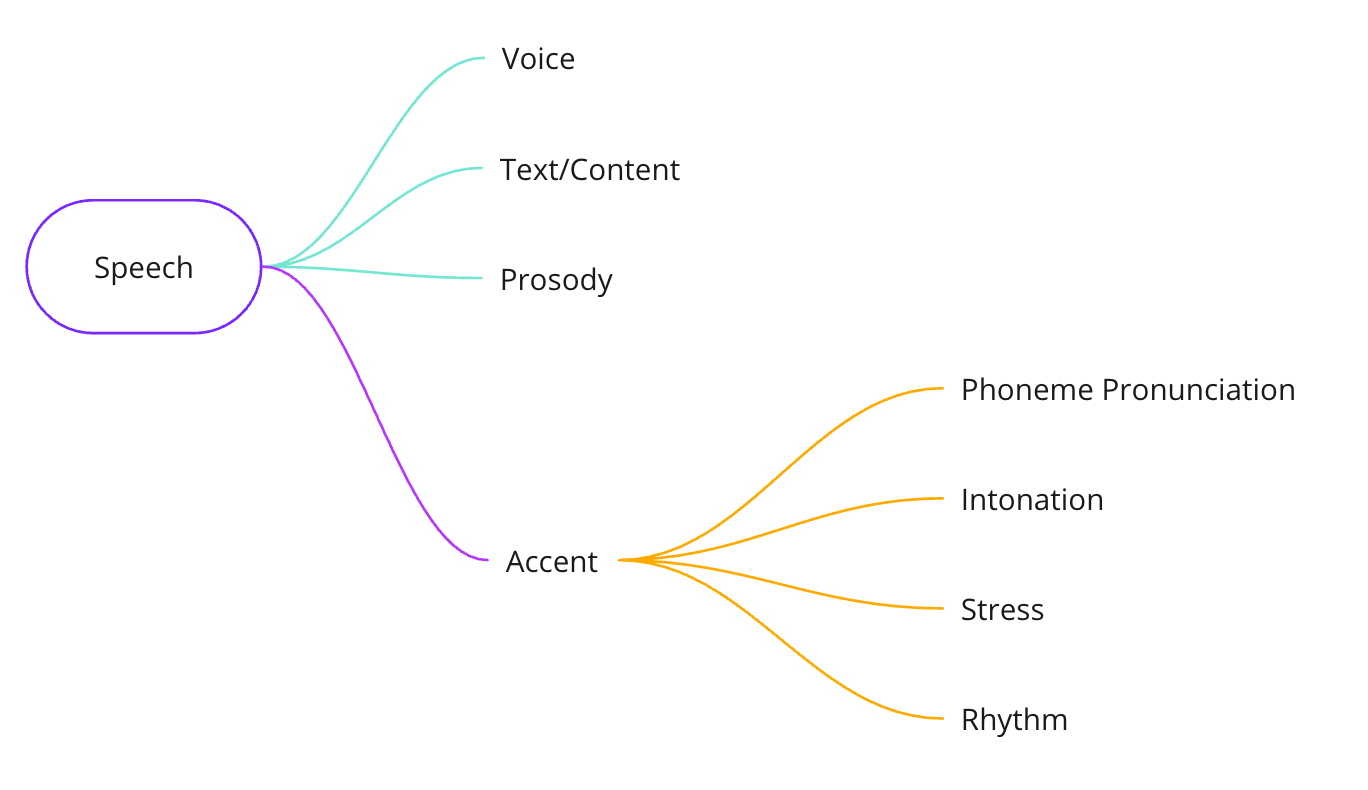
In order to localize or translate an accent, three of these parts must be changed – phoneme pronunciation, intonation, and stress. Doing this in real-time is an extremely difficult technical problem.
While there are numerous technical challenges in building this technology, we will focus on eight majors.
- Data Collection
- Speech Synthesis
- Low Latency
- Background Noises and Voices
- Acoustic Conditions
- Maintaining Correct Intonation
- Maintaining Speaker’s Voice
- Wrong Pronunciations
Let’s discuss them individually.
1) Data collection
Collecting accented speech data is a tough process. The data must be highly representative of different dialects spoken in the source language. Also, it should cover various voices, age groups, speaking rates, prosody, and emotion variations. For call centers, it is preferable to have natural conversational speech samples with rich vocabulary targeted for the use case.
There are two options: buy ready data or record and capture the data in-house. In practice, both can be done in parallel.
An ideal dataset would consist of thousands of hours of speech where source accent utterance is mapped to each target accent utterance and aligned with it accurately.
However, getting precise alignment is exceedingly challenging due to variations in the duration of phoneme pronunciations. Nonetheless, improved alignment accuracy contributes to superior results.
2) Speech synthesis
The speech synthesis part of the model, which is sometimes referred to as the vocoder algorithm in research, should produce a high-quality, natural-sounding speech waveform. It is expected to sound closer to the target accent, have high intelligibility, be low-latency, convey natural emotions and intonation, be robust against noise and background voices, and be compatible with various acoustic environments.
3) Low latency
As studies by the International Telecommunication Union show (G.114 recommendation), speech transmission maintains acceptable quality during real-time communication if the one-way delay is less than approximately 300 ms. Therefore, the latency of the end-to-end accent localization system should be within that range to ensure it does not impact the quality of real-time conversation.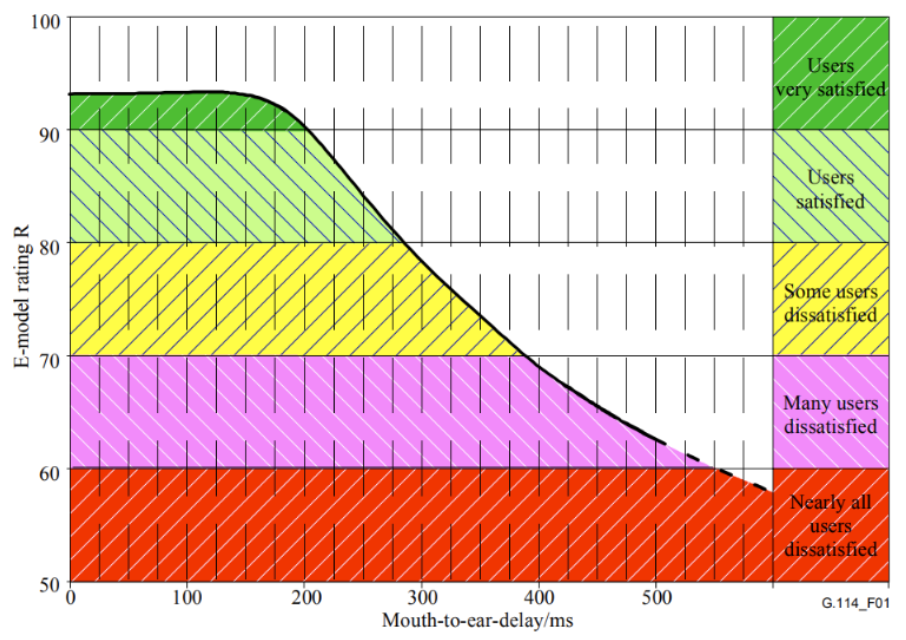
There are two ways to run this technology: locally or in the cloud. While both have theoretical advantages, in practice, more systems with similar characteristics (e.g. AI-powered noise cancellation, voice conversion, etc.) have been successfully deployed locally. This is mostly due to hard requirements around latency and scale.
To be able to run locally, the end-to-end neural network must be small and highly optimized, which requires significant engineering resources.
4) Background noise and voices
Having a sophisticated noise cancellation system is crucial for this Voice AI technology. Otherwise, the speech synthesizing model will generate unwanted artifacts.
Not only should it eliminate the input background noise but also the input background voices. Any sound that is not the speaker’s voice must be suppressed.
This is especially important in call center environments where multiple agents sit in close proximity to each other, serving multiple customers simultaneously over the phone.

Detecting and filtering out other human voices is a very difficult problem. As of this writing, to our knowledge, there is only one system doing it properly today – Krisp’s AI Noise Cancellation technology.
5) Acoustic conditions
Acoustic conditions differ for call center agents. The sheer volume of combinations of device microphones and room setups (accountable for room echo) makes it very difficult to design a robust system against such input variations.

6) Maintaining the speaker’s intonation
Not transferring the speaker’s intonation in the generated speech will result in a robotic speech that sounds worse than the original.
Krisp addressed this issue by developing an algorithm capturing input speaker’s intonation details in real-time and leveraging this information in the synthesized speech. Solving this challenging problem allowed us to increase the naturalness of the generated speech.

7) Maintaining the speaker’s voice
It is desirable to maintain the speaker’s vocal characteristics (e.g., formants, timbre) while generating output speech. This is a major challenge and one potential solution is designing the speech synthesis component so that it generates speech conditioned on the input speaker’s voice ‘fingerprint’ – a special vector encoding a unique acoustic representation of an individual’s voice.

8) Wrong pronunciations
Mispronounced words can be difficult to correct in real-time, as the general setup would require separate automatic speech recognition and language modeling blocks, which introduce significant algorithmic delays and fail to meet the low latency criterion.
3 technical approaches to AI Accent Localization
Approach 1: Speech → STT → Speech
One approach to accent localization involves applying Speech-to-Text (STT) to the input speech and subsequently utilizing Text-to-Speech (TTS) algorithms to synthesize the target speech.
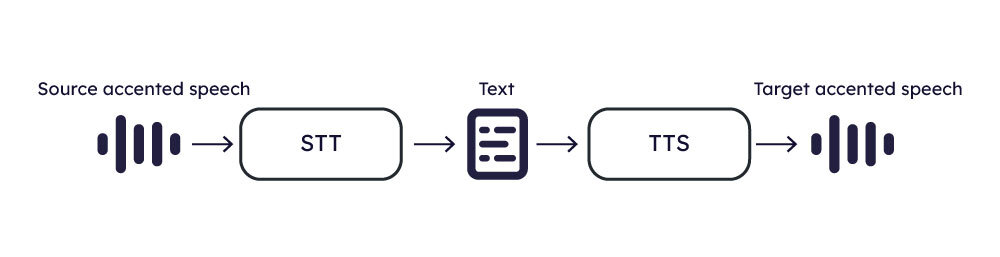
This approach is relatively straightforward and involves common technologies like STT and TTS, making it conceptually simple to implement.
STT and TTS are well-established, with existing solutions and tools readily available.
Integration into the algorithm can leverage these technologies effectively. These represent the strengths of the method, yet it is not without its drawbacks. There are 3 of them:
- The difficulty of having accent-robust STT with a very low word error rate.
- The TTS algorithm must possess capabilities to manage emotions, intonation, and speaking rate, which should come from original accented input and produce speech that sounds natural.
- Algorithmic delay within the STT plus TTS pipeline may fall short of meeting the demands of real-time communication.
Approach 2: Speech → Phoneme → Speech
First, let’s define what a phoneme is. A phoneme is the smallest unit of sound in a language that can distinguish words from each other. It is an abstract concept used in linguistics to understand how language sounds function to encode meaning. Different languages have different sets of phonemes; the number of phonemes in a language can vary widely, from as few as 11 to over 100. Phonemes themselves do not have inherent meaning but work within the system of a language to create meaningful distinctions between words. For example, the English phonemes /p/ and /b/ differentiate the words “pat” and “bat.”
The objective is to first map the source speech to a phonetic representation, then map the result to the target speech’s phonetic representation (content), and then synthesize the target speech from it.
This approach enables the achievement of comparatively smaller delays than Approach 1. However, it faces the challenge of generating natural-sounding speech output, and reliance solely on phoneme information is insufficient for accurately reconstructing the target speech. To address this issue, the model should also extract additional features such as speaking rate, emotions, loudness, and vocal characteristics. These features should then be integrated with the target speech content to synthesize the target speech based on these attributes.
Approach 3: Speech → Speech
Another approach is to create parallel data using deep learning or digital signal processing techniques. This entails generating a native target-accent sounding output for each accented speech input, maintaining consistent emotions, naturalness, and vocal characteristics, and achieving an ideal frame-by-frame alignment with the input data.
If high-quality parallel data are available, the accent localization model can be implemented as a single neural network algorithm trained to directly map input accented speech to target native speech.
The biggest challenge of this approach is obtaining high-quality parallel data.The quality of the final model directly depends on the quality of parallel data.
Another drawback is the lack of integrated explicit control over speech characteristics, such as intonation, voice, or loudness. Without this control, the model may fail to accurately learn these important aspects.
How to measure the quality AI Accent Localization output
High-quality output of accent localization technology should:
- Be intelligible
- Have little or no accentedness (the degree of deviation from the native accent)
- Sound natural
To evaluate these quality features, we use the following objective metrics:
- Word Error Rate (WER)
- Phoneme Error Rate (PER)
- Naturalness prediction
Word Error Rate (WER)
WER is a crucial metric used to assess STT systems’ accuracy. It quantifies the word level errors of predicted transcription compared to a reference transcription.
To compute WER we use a high-quality STT system on generated speech from test audios that come with predefined transcripts.
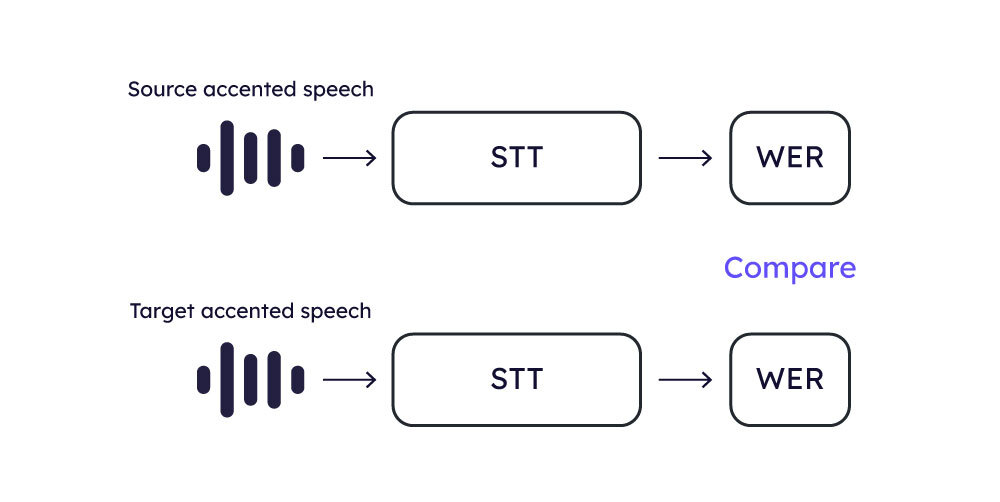
The evaluation process is the following:
- The test set is processed through the candidate accent localization (AL) model to obtain the converted speech samples.
- These converted speech samples are then fed into the STT system to generate the predicted transcriptions.
- WER is calculated using the predicted and the reference texts.
The assumption in this methodology is that a model demonstrating better intelligibility will have a lower WER score.
Phoneme Error Rate (PER)
The AL model may retain some aspects of the original accent in the converted speech, notably in the pronunciation of phonemes. Given that state-of-the-art STT systems are designed to be robust to various accents, they might still achieve low WER scores even when the speech exhibits accented characteristics.
To identify phonetic mistakes, we employ the Phoneme Error Rate (PER) as a more suitable metric than WER. PER is calculated in a manner similar to WER, focusing on phoneme errors in the transcription, rather than word-level errors.
For PER calculation, a high-quality phoneme recognition model is used, such as the one available at https://huggingface.co/facebook/wav2vec2-xlsr-53-espeak-cv-ft. The evaluation process is as follows:
- The test set is processed by the candidate AL model to produce the converted speech samples.
- These converted speech samples are fed into the phoneme recognition system to obtain the predicted phonetic transcriptions.
- PER is calculated using predicted and reference phonetic transcriptions.
This method addresses the phonetic precision of the AL model to a certain extent.
Naturalness Prediction
To assess the naturalness of generated speech, one common method involves conducting subjective listening tests. In these tests, listeners are asked to rate the speech samples on a 5-point scale, where 1 denotes very robotic speech and 5 denotes highly natural speech.
The average of these ratings, known as the Mean Opinion Score (MOS), serves as the naturalness score for the given sample.
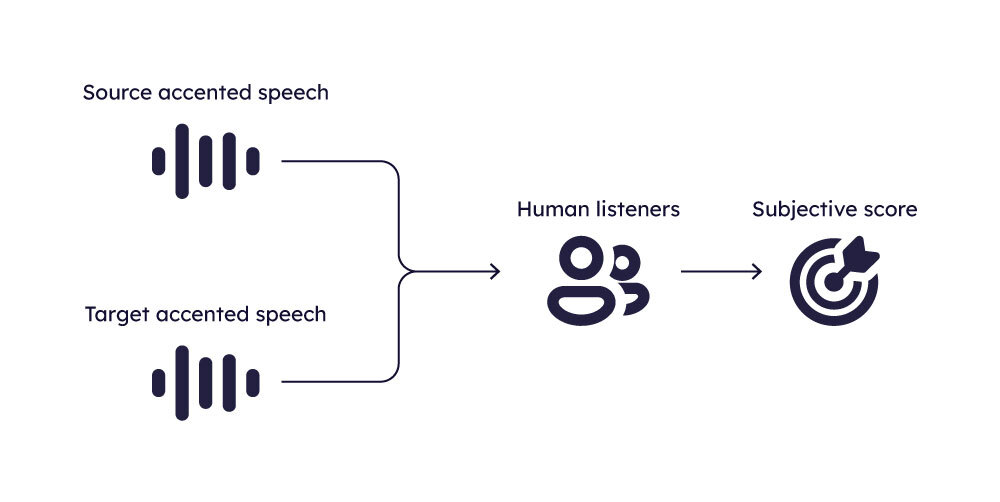
In addition to subjective evaluations, obtaining an objective measure of speech naturalness is also feasible. It is a distinct research direction—predicting the naturalness of generated speech using AI. Models in this domain are developed using large datasets comprised of subjective listening assessments of the naturalness of generated speech (obtained from various speech-generating systems like text-to-speech, voice conversion, etc).
These models are designed to predict the MOS score for a speech sample based on its characteristics. Developing such models is a great challenge and remains an active area of research. Therefore, one should be careful when using these models to predict naturalness. Notable examples include the self-supervised learned MOS predictor and NISQA, which represent significant advances in this field.
In addition to objective metrics mentioned above, we conduct subjective listening tests and calculate objective scores using MOS predictors. We also manually examine the quality of these objective assessments. This approach enables a thorough analysis of the naturalness of our AL models, ensuring a well-rounded evaluation of their performance.
AI Accent Localization model training and inference
The following diagrams show how the training and inference are organized.
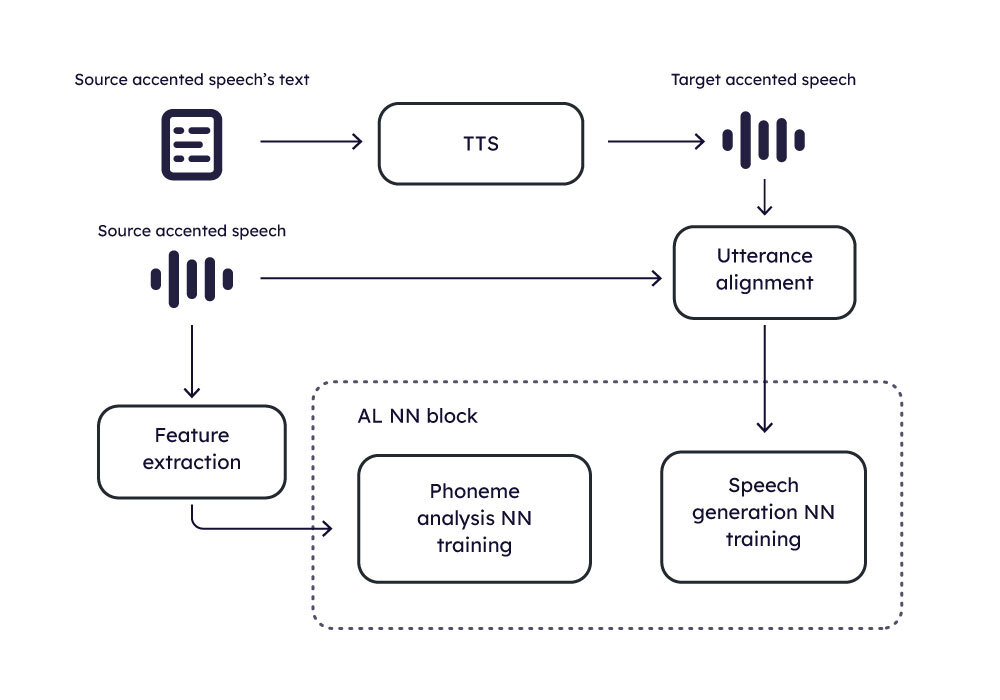
AI Training
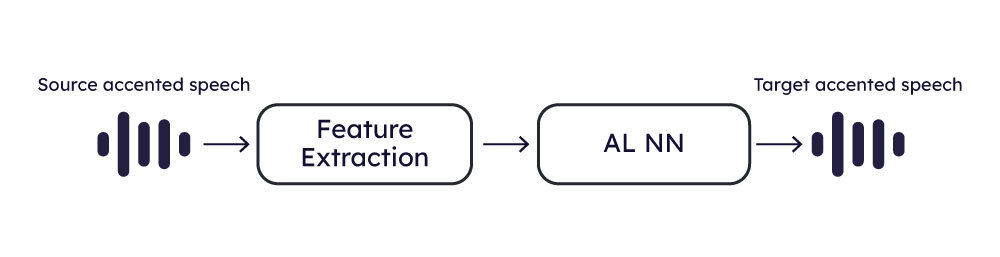
AI Inference
Closing
In navigating the complexities of global call center operations, AI Accent Localization technology is a disruptive innovation, primed to bridge language barriers and elevate customer service while expanding talent pools, reducing costs, and revolutionizing CX.
References
- https://www.smartcommunications.com/resources/news/benchmark-report-2023-2/
- https://info.siteselectiongroup.com/blog/site-selection-group-releases-2023-global-call-center-location-trend-report
- https://www.siteselectiongroup.com/whitepapers
- https://www.reuters.com/article/idUSTRE5AN37C/
The post Deep Dive: AI’s Role in Accent Localization for Call Centers appeared first on Krisp.
]]>The post 8 easy steps to improve voice quality in Audacity appeared first on Krisp.
]]>Audacity is an easy-to-use and completely free multi-track audio editor and recorder for Windows, macOS, GNU/Linux and other operating systems. It’s great for audio recording and podcasting.
If you’re overwhelmed at what this audio software can do, don’t be! We’ve compiled a handy list on how to improve your audio projects using Audacity.
Whether you’re a podcaster, a sound recordist, or simply someone who wants to sharpen up some audio you have, look no further than this guide on mastering Audacity for voice quality to achieve professional results.
#1 Use the Noise Profile
Firstly, it’s important to clear any background noise. To do that, you just need to understand what frequencies you want to remove. Audacity’s Noise Profile will do just that. Click Effect> Noise Production, and then select Noise Profile. This means you can analyse the audio section and see exactly which frequencies you need removing.
#2 Use Noise Remover Next, it’s time to remove the noise – but hopefully you won’t have much. Select the entire section of waveform from which you want to reduce the noise, then set the Noise Reduction parameters. Use trial and error, adjusting the sliders and listening as you go along.
You can also use Krisp to remove noise, a simple and easy tool that seamlessly works with Audacity to remove background noise. What’s more, it works in real-time, meaning the noises are removed during your audio recording.
So there’s no need to go back and delete the noise when you use noiseless recordings using Krisp with Audacity. After you download and install Krisp, configuring with Audacity is a piece of cake.
Hover over the audio settings in Audacity and select Krisp microphone. Then let it perform its noise cancelling magic. Simple!
To listen while Audacity is recording, enable what is known as software or hardware play-through. If you use software play-through and want to listen to the input without recording it, you need to also left-click in the Recording Meter Toolbar to turn on monitoring.
#3 Use the Normalizer
The Normalizer feature in Audacity is the next best shout for improving voice quality on your audio recordings. Immediately after recording capture (or import) of your audio, this effect should be used solely to remove any DC offset that may be present with no amplitude adjustment applied at this stage.
Use the Normalize effect to set the peak amplitude of a single track, make multiple tracks have the same peak amplitude and equalize the balance of left and right channels of stereo tracks.
This will ensure your podcast or audio recording has that all-round audio goodness when listened to through headphones.
#4 Use the Compressor
Compressing the audio is used for increasing the volume of your vocals so that if you are talking too quiet, it will make you louder. As you can imagine, this is particularly helpful for podcasters with low quality microphones.
Here’s how to do it:
Click on Effects: Compressor and keep the settings on the following levels:
Threshold = -18db
Noise Floor = -40db
Ratio = 2.5:1
Attack Time = 1.81 secs
Release Time = 11.1 secs
Don’t be afraid to play around with these settings to get the volume just right. If you move the cursor to the left, you’ll hear more background noise.
It’s important to keep the audio level out of the red (below 0db), as this can cause distortion. Use the level control to turn it down if this occurs.
#5 Use the Equalizer
So, another cool Audacity setting is the Equalizer. It’s a tool for manipulating the frequency content of sounds, it allows you to set the
balance between the low, mid, and high frequencies. Understanding how these work will make a huge difference to your audio quality.
In women, the frequency range is about 165 Hz to 255 Hz. In men it is a bit lower, 85 Hz to 155 Hz usually. This gives you a more specific range to tinker with it so you don’t put a ton of time and effort into ranges that really don’t affect voice quality.
Use the preview button to monitor the settings and tweak until your Audacity fle sounds clear. Usually a slight dip to the low end or a slight boost will make the world of difference. Once you’re happy with the sound, click “OK” to save changes.
#6 Use Spectrogram
When evaluating your audio quality, it’s important to use the Spectrogram view for voice quality in Audacity.
The Spectrogram view of your audio track provides a visual indication of how the energy in different frequency bands changes over time. That means it can show sudden onset of a sound – making it easier to see clicks and other glitches. It’s also better to use this view for lining up beats in this view rather than in one of the waveform views.
#7 Use The AutoDuck Effect
Have a podcast and you find that sometimes your background music or jingle can drown out your voice? Yeah, you don’t want that.
Try using the AutoDuck to improve the voice quality of your audio project. This Auto-Duck effect is inbuilt into voice quality in Audacity.
It uses a ‘control’ track to lower the level of the ducked track. That means that when the music is playing at full volume, it will detect when the narrator starts speaking. Clever, right?
This then lowers the level of the music track so it is quieter than the narrator. When the narrator finishes, the music returns, or releases to its original level.
#8 Use Bass And Treble Boost
When refining Audacity for voice quality, remember to utilize the bass and treble boost functions with caution, as they can alter the overall frequency balance and potentially affect the final audio level. The Bass and Treble functions increase or decrease the lower frequencies and higher frequencies of your audio independently. They operate just like the bass, treble and volume controls on a domestic stereo system.
Things to remember when using this function:
- Applying a boost to the bass or treble will tend to increase the overall level.
- Reducing the bass or treble may make the final level too quiet.
- If both the treble and bass frequencies are increased and the overall volume lowered, the overall effect means there’s a reduction in the middle frequencies. Similarly, reducing both the bass and treble and increasing the volume has an overall effect of boosting the middle frequencies.
Combine Audacity and Krisp for the perfect audio production
Audacity is an ideal program for achieving a better professional audio recording of your voice, especially if you’re a podcaster.
Try Audacity for your next project, but be sure to install Krisp so you don’t spend many hours going back and removing all the background noise!
Used Audacity and Krisp together to improve your voice in Audacity? We’d love to hear your finished results!
Read next: 15 Best Voice Recording Software in 2021
The post 8 easy steps to improve voice quality in Audacity appeared first on Krisp.
]]>